


Given that lead is such a potent neurotoxin, getting the largest number of lead drinking water service lines replaced as quickly as possible is an obvious top priority. But it may not be immediately apparent why you’d want to use artificial intelligence and machine learning as part of these efforts. After all, we’re not looking for lost treasures. Most U.S. cities installed their drinking water service lines less than 100 years ago.
Jared Webb, Chief Data Scientist for BlueConduit, summarizes the problem as a tragically human one:
“Of course people knew when they put the service lines in what was where. But … every decade or so you switch your system for storing that information and keeping track of that information. Sometimes it gets transferred incorrectly, or incompletely, or lost altogether. Now we have large swaths of many water systems where it is simply unknown what is in the ground. And then there are other places where they might have something written down about what material is moving water, but that something is wrong.”
Relying on those flawed records—and not asking too many questions—can put you in a situation where you erroneously believe you’re actually quite successful at removing lead service lines. (A classic example of having a high “hit rate” marred by unknown “sensitivity.”)
“It’s sadly easy to have a very high hit rate,” Jared notes, “by just going to neighborhoods where you have very good records and digging in the places where there is hardly any uncertainty that there is lead [service line]. … You can just stop there and say ‘I have a 90% hit rate; we were so successful!’”
This sort of magical thinking is extremely tempting, because that high hit rate is so easy to communicate and so reassuring to members of your community.
But succumbing to the allure of an easy answer leaves an unknown amount of lead in the ground, continuing to do harm.
Using Machine Learning to Improve Statistical Model Accuracy (and Save Money)
“We know lead service lines are harmful,” Jared adds. “But we also know there isn’t enough money to dig up every single yard of every house built before 1986. If you want to get as much lead as possible with the resources we have, you want good statistical thinking.”
Machine learning-based data science tools have proven to be the key to supercharging our statistical thinking around the challenge of finding those unknown and forgotten lead service lines.
BlueConduit’s approach starts by assuming that, as Jared puts it,
“What’s written down is something to learn from, not something to take as ground truth.”
With those historic records as a jumping off point, we select a representative sample of service lines for the water system to dig up, checking the accuracy of existing records and exploring unknowns.
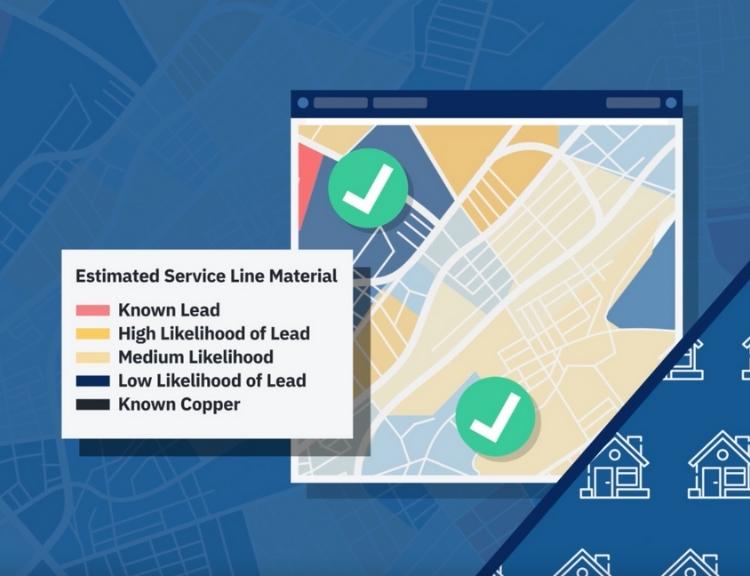
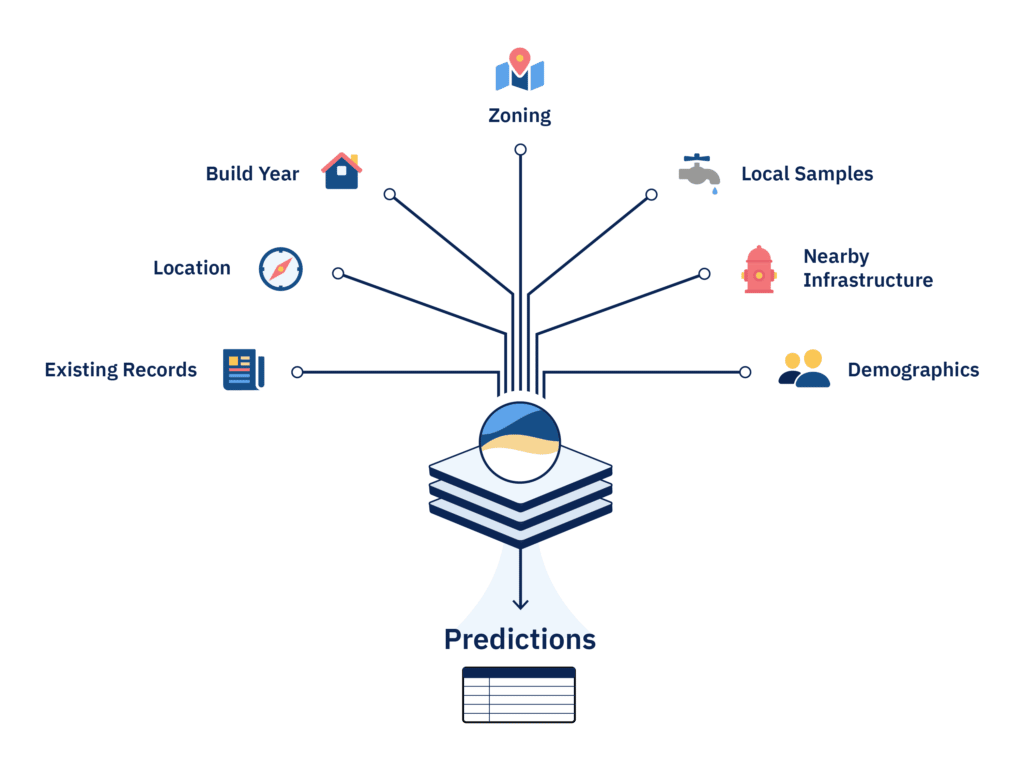
These findings, along with a range of other information about the local built environment (e.g. build year, zoning, location, demographics, information on nearby infrastructure like fire hydrants, local samples, etc.) is then used to train BlueConduit’s machine-learning model. That artificial intelligence then makes predictions for all of the houses in the defined area. As digging and line replacement commences, findings from those digs are regularly fed back into the model so it can improve its predictions.
Outcomes Confirm the Superiority of Data Science-Backed Predictions
AI-powered data science visualization tools have proven quite successful at improving the sensitivity of lead service line removal efforts. For example, prior to the Flint Water Crisis, existing records led city officials to believe that only around 10% to 20% of Flint’s service lines were lead. In 2016, BlueConduit began exploring the Flint water system. Their machine-learning model indicated that it seemed much more likely that roughly 50% of Flint’s water lines were lead. Throughout 2016 and 2017, Flint replaced lead lines based on BlueConduit’s recommendations. During this project the city had an 80% hit rate on those excavations. Ultimately, in 2019, after 20,000 excavations, the city verified that 50% of their inventory had indeed been lead lines.
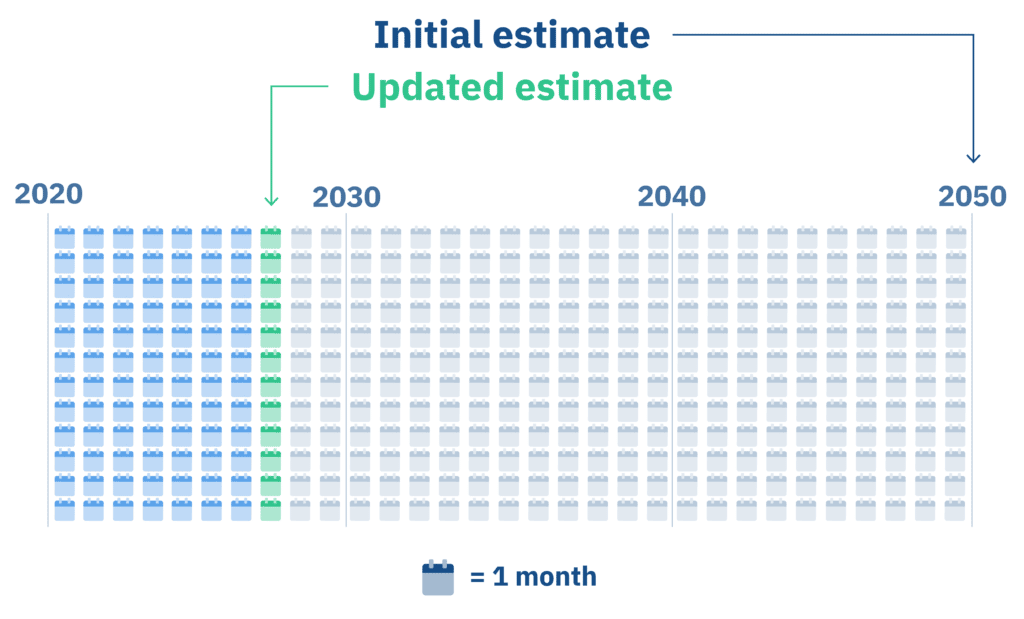
Importantly, AI-guided environmental data science hasn’t simply proven itself to be more precise and more sensitive; it’s also significantly less expensive and much faster. Flint saved tens of millions of dollars in unneeded excavations, freeing up those resources to further secure safe drinking water for more of their citizens. Similarly, by harnessing the power of AI, Toledo massively accelerated their lead service line removal program. Toledo’s initial estimate was that it would take approximately 30 years to replace the thousands of lead service lines in their city. They now project that they’ll have replaced every lead service line in Toledo by 2027.



